Support
Where to ask for support
Our team is always around, almost 24/7 and you can reach us by:
Frequently Asked Questions
Who is WordLift for?
WordLift is for all bloggers, journalists, and content marketers publishing and fighting for readers’ attention on the web. WordLift democratizes the field, bringing to the hands of all web content creators the technology that web publisher giants such as Google, Facebook and the BBC are using to organize and monetize their content. WordLift helps you create richer and more engaging content, optimizes it for all search engines and efficiently organizes your content creation process, allowing you to reach and speak directly to your tribe.
Why shall I use WordLift?
Organizing web content around an internal vocabulary rather than traditional web pages helps both users and machines finding and accessing it, improving navigation, content re-use, content repurposing, and search engine rankings. WordLift organizes content, reducing the complexity of content management and content marketing operations, letting bloggers and site owners focus on stories and communities. WordLift enriches your content with contextual information, links, and media, from custom vocabularies and/or the wealth of open data available on the web, bringing your user experience to a new level of engagement. WordLift connects content with cross-media discovery and recommendations widgets, increasing content quality, exposure, trustworthiness and readership engagement. WordLift optimizes content, complementing the offer of plug-ins such as SEO Ultimate + or Yoast, automatically adding schema markup to your text, allowing all search engines to properly index your pages and deliver more traffic to your site.
How does it work?
To know more about how WordLift works, please watch the step by step video tutorials on our website.
WordLift works in subsequent stages.
- The first step provides a full text analysis and suggests concepts and relationships found in open vocabularies (such as DBpedia, Wikidata, GeoNames, etc) to help writers classify and enrich their content and structure it for search engines like Google, according to schema.org vocabulary.
- Writers can then create new entities, to complement the ones suggested automatically, and to be published as part of a proprietary vocabulary, acting both as a reference and a search magnet for their readers, according to the editorial plans.
- WordLift also assists writers suggesting links, media and providing a set of powerful visualization widgets to connect and recommend alternative content, to boost readers’ engagement.
- Finally WordLift provides means to record all these relationships in a graph database allowing search queries like “find all contents related to concept_y and relevant for target_z”.
What are the languages supported by WordLift?
WordLift currently supports 32 languages: Chinese, Danish, German, English, French, Italian, Dutch, Russian, Spanish, Portuguese, Swedish, Turkish, Albanian, Belarusian, Bulgarian, Catalan, Croatian, Czech, Estonian, Finnish, Hungarian, Icelandic, Indonesian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Serbian, Slovak, Slovenian, Ukrainian.
WordLift supports one language at the time. The main language of the website can be configured from the WordLift settings. Review the configuration settings for more information.
Is there a free trial?
Yes! All of our subscriptions come with a 14-day free trial. If after two weeks you are not happy with WordLift, contact us and we will cancel your subscription, no questions asked. In addition, with the purchase of our 12-month packages, we offer 20% discount. Check it out!
Who owns the structured metadata created with WordLift?
You do! We believe content creators should retain the commercial value of their content and all the data they create and exploit it through new business models based on content syndication, data-as-a-service and a stronger relationship with their audience. You can open your datasets to the public, attaching to it a free or a commercial licence. Otherwise, use your data to feed chat bots such as Facebook Messenger or Telegram, providing live feed updates on your activity and/or automatic customer service in real time.
What happens if I stop using WordLift?
- If you stop paying for your subscription, but keep the plugin on your site, all the entities, metadata and pages you created with wordlift will still be available on your site - you won't be able to update it any longer, but they will still work just fine as they were at the moment you removed the key. The data you’ve created belongs to you and you can always request to us a data dump that is available in various machine-readable formats.
- if you deactivate the plugin instead, the vocabulary (metadata, entity and pages) will disappear from your dashboard, but everything you created is stored in your website Database in WordPress, and you will be able to download it, transfer it or re-activate it again anytime from the plugin menu.
- Turning off WordLift on our side, it would be like turning off all the keys and un-publish all the linked data you’ve created, not the plug-in itself, so it will be like ##1 - you could get the data back from us and re-publish it as linked data on your own infrastructure.
- WordLift's technology is entirely open source: it takes development skills, infrastructure and some wisdom to nicely bring all the pieces together without our support.
- Your vocabulary (article metadata and entities) are published as linked data and you can always request a data dump in any of the following formats: RDF/XML, Turtle, N3, JSON-LD.
How can I download my Knowledge Graph data?
You can export your entire Knowledge Graph dataset using the Dataset Export API endpoint. The API supports multiple formats including RDF/XML, JSON-LD, Turtle, and N3.
Quick example using wget:
wget 'https://api.wordlift.io/dataset/export' \
--header="Authorization: Key <WORDLIFT_API_KEY>" \
--header="Accept: application/ld+json" \
-O "export.jsonld"
Replace <WORDLIFT_API_KEY> with your actual WordLift API key. For detailed documentation and more examples, see the Export section in the KG-REST API documentation.
Is WordLift Secure?
Security has been a consideration from day one. We have worked for many years in high-security environments such as parliaments and telco operators and we leverage on all of our experience to protect the data of our users.
So, what are some of the ways we do this?
- WordLift plugin and front end only use SSL.
- Your data from the WordLift store is in a dedicated database, with access granted only to the WordLift store web site account originating from the WordLift store network address.
- Keys for accessing your account page are transmitted securely over SSL and encrypted from the moment we receive them.
- Any data transmitted between WordLift and our server farm is done over SSL.
- Your data is not shared with or handled by any other services or companies, with the exception of the data published as open data.
- WordLift itself is a small team, which limits the number of people with any access to your data.
- There are regular security reviews of all WordLift servers and components.
- You can ask us to delete your account information at any time. Contact us by by email, or by making a request here.
If you have any other questions, concerns, or want to clarify anything listed on this page, please let us know.
Why and how should I customize the url of the entity pages created in my vocabulary?
When selecting or creating new entities with WordLift, you are actively building your internal vocabulary, adding pages to your website. When you first built your website, you chose a pattern for the url of the pages you were going to add, such as www.domain.com/name-of-the-page or www.domain.com/seo-keyword/name-of-the-page. The same applies with all the pages created with WordLift inside your vocabulary.
- By default WordLift will add the word “vocabulary” between your root domain and the name of the page: www.domain.com/vocabulary/name-of-the-entity-page.
- You can delete the word vocabulary if you want the new entity page to be inside your root domain folder: www.domain.com/name-of-the-entity-page.
- Or you can replace vocabulary with another keyword (or keywords) of your choice, for SEO or branding reason: www.domain.com/seo-keyword/name-of-the-entity-page.
Why is it important to organize my content and publish it as Linked Data?
Organizing web content around concepts rather than traditional web pages helps both users and machines finding and accessing it, improves navigation, content re-use, content repurposing and search engine rankings. Enriching content with contextual information, links and media, from custom vocabularies and/or the wealth of open data available on the web, brings the user experience to a new level of engagement. Structuring content with richer metadata and publishing it as linked data makes it discoverable and searchable, providing new ways of reaching targets.
Why is WordLift innovative?
WordLift is first-to-market following a “content organization” approach which allows the classification and direct exploitation of proprietary content and structured metadata. Wordlift helps publishers create their knowledge graph, exploit it and monetize it.
Finally WordLift complements the offer of plug-ins such as SEO Ultimate + or Yoast automatically adding schema markup to content, allowing search engines to properly index pages, increasing traffic from organic searches.
What is content enrichment?
Content enrichment is a processes used to refine and improve textual content by embedding structured data (metadata) on web pages. This metadata is made available to search engines and other data consumers.
What entity types are supported and how they map to Schema.org?
Thing, Person, Place, Event, Organization, LocalBusiness, Creative Work and Recipe are the supported types. Review the Edit Entity page for more information.
When should I create a new entity?
You should create a new entity when this is directly relevant to the content you're writing and it doesn't already exist. When an entity is properly recognised by WordLift you shall edit this entity rather then creating a new one.
You can add as many entities as you like.
What are the guidelines for creating new entities to annotate a blog post or a page?
A basic guideline for adding a new entity is:
"people should create entities that a librarian would plausibly use to classify the content as if it was a book."
The purpose of using WordLift is to (1) categorize your content, (2) help people find content of interest to them, and (3) help WordLift describe your contents in machine-readable format so that other computers can re-use it.
In some cases key concepts that are important for (1), (2) and (3) are not automatically detected by WordLift and need to be taught. To teach WordLift new concepts a new entity shall be created.
When entities already exist on a website in the form of posts or pages we shall always avoid creating a new entity and instead turn these posts or pages into entities. Here is how.
People should add entities that are accurate and directly relevant to the content they're writing.
Excessively broad entities should not be added to content.
Content should not be overloaded with entities to increase its distribution online. As a general guideline, 6–8 entities should be adequate for most blog posts (based on the lenght of the article). If an article has too many entities it may be that some of the entities could be replaced with a single broader entity.
All entities shall be matched to the proper language of the content. There are two important articles to read on this topic:
- 8 Rules To Create A Vocabulary For Your WordPress Website
- Entity Based SEO: How To Optimize Your Entity Vocabulary
How can I search for the equivalent entity in the web of data?
A published datasets like the knowledge graph that users create with WordLift shall link to other existing datasets using the OWL owl:sameAs property. This property creates an equivalence class between two nodes of an RDF graph. Tim Berners Lee in his "Linked Data" note of 2006 outlined 4 principles of linked data:
- Use URIs to name (identify) things.
- Use HTTP URIs so that these things can be looked up (interpreted, "dereferenced").
- Provide useful information about what a name identifies when it's looked up, using open standards such as RDF, SPARQL, etc.
- Refer to other things using their HTTP URI-based names when publishing data on the Web.
Specifically the 4th linked data principle is meant to ensure a Web of data and not just a set of unconnected data islands. WordLift during the analysis automatically interlinks all detected entities with several datasets (DBpedia, Yago, Freebase etc.) but what if we are creating a new entity from scratch? How can we find an equivalent resource in the Web of linked data?
There are basically four ways of doing it. The goal is to provide an information that can be understood by semantic search engines like Google, Bing and Yandex:
- use WordLift sameAs search box. WordLift will look for entities in Wikidata, DBpedia and on the datasets configured behind the WordLift key for the equivalent entity. This feature has been introduced with WordLift 3.15 learn more about this feature here.
- ask Google Search a query by adding "site:dbpedia.org" to the name of the entity (ie "site:dbpedia.org apache marmotta"). Google will provide a list of results, chose the URL that start with dbpedia.org/page/ (ie dbpedia.org/page/Apache_Marmotta), replace
/page/with/resource/and you will have theowl:sameAslink to be added to your entity; - look for the entity in Wikidata by using the search bar on the wikidata website. The search bar is on the top right corner. The URL for the equivalent entity of Apache Marmotta in Wikidata is https://www.wikidata.org/wiki/Q16928009;
- use the Google Knowledge Graph Search API (here is a link to the documentation by Google). You will need an API Key from Google. Using your personal API key you will be able to search the Google Knowledge Graph with simple HTTP request. Here is an example
https://kgsearch.googleapis.com/v1/entities:search?query=andrea+volpini&key=API_KEY&limit=1&indent=True(simply replaceAPI_KEYwith your personal API Key). The API responds with a JSON LD; look for themachine idthat is located underitemListElement>result>@id. This should be something likekg:/m/0djtw2hnow take the id and rewrite it by adding in front http://rdf.freebase.com/ns/ than replace/m/with/m.and you should have something like: http://rdf.freebase.com/ns/m.0ndhxqz.
While Freebase no longer exists the machine id remains valid. We prefer to have such links in the owl:sameAs property of entities created with WordLift as these links point to RDF resources. As a matter of fact DBpedia, to interlink with Freebase, still uses these type of links rather than just the machine id.
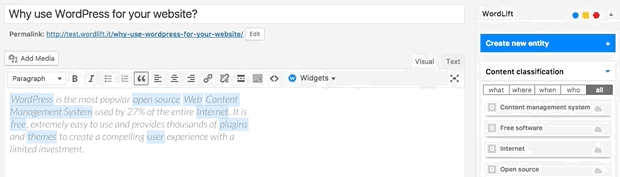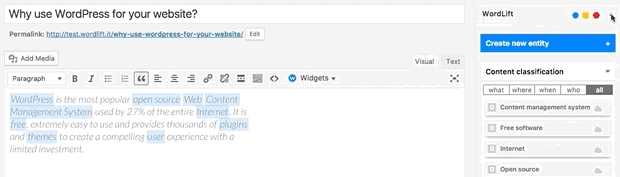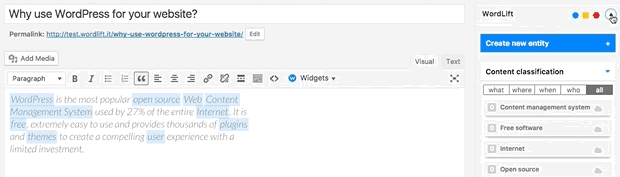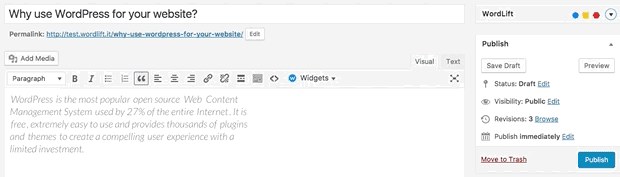
Can I prevent the analysis to run?
Yes. You can switch WordLift's analysis ON and OFF by clicking on the open|close arrow on the top right corner of the WordLift's Edit widget. See the .gif below:
What factors determine Wordlift's rating of an entity?
Can I prevent WordLift from loading Wikimedia images?
Yes. You can prevent WordLift from loading images that come from Wikipedia. In your wp-config.php, add the following line:
define( 'WL_EXCLUDE_IMAGES_REGEX', 'https?://[^.]*\.wikimedia\.org/.*' );
before the line
/* That's all, stop editing! Happy blogging. */
I have already published a JSON-LD on the page. How can I integrate it with the JSON-LD that WordLift creates?
We provide several options to help you integrate WordLift with the existing markup:
- Completely disable WordLift’s JSON-LD by adding
add_filter( 'wl_jsonld_enabled', '__return_false' );in your theme. - Edit WordLift’s JSON-LD by using WordPress filters (this requires PHP development skills), see here on Stack Overflow.
- Use WordLift’s Mappings to customize the JSON-LD using the UI provided by the plugin in Dashboard > WordLift > Mappings
- Augment WordLift’s JSON-LD by adding your own custom JSON-LD matching the same @id (in this case Google will merge the data from WordLift’s JSON-LD and your JSON-LD)
What factors determine Wordlift's rating of an entity?
The entity rating in WordLift takes under account the following factors:
- Every entity should be linked to one or more related posts.
- Every entity should have its own description.
- Every entity should link to other entities - when we select other entities to enrich the description of an entity we create relationships in the site's knowledge graph.
- Entities, just like any post in WordPress, can be kept as draft. Only when we publish them they become available in the analysis and we can use them to classify our contents.
- Entities shall have a featured image. When we add a featured image to an entity we’re adding the
schema-org:imageattribute to it. - Every entity (unless we’re creating something completely new) should be interlinked with the same entity contained in at least one other dataset. This is called data interlinking and can be done by adding a link to the equivalent entity using the
sameAsattribute. - Every entity has a type (i.e. Person, Place, Organization, …) and every type has its own set of properties. When we complete all the properties of an entity we increase the entity visibility and usefulness.
I have a vocabulary term appearing several times in a page, should I link all of the occurrences to the term, or just once per page?
While on an average length blog post (> 500 words) we shall use a limited number of entities to classify the content, there is not an actual limit for the number of internal links pointing to the same entity page.
In SEO the link juice is transferred equally from every single link: if Google transfers let's say 85% of your article's Page Rank each link will equally get its own share. Five links pointing to the same page will therefore transfer the same amount of link juice of one single link. If I link too many different pages by annotating the blog post with too many entities the link juice will be diluted (and this is why we don't expect to have too many entities per article).
Now we need to consider the following:
- if on the page (including navigation links, footer links and so on) you have too many links already - you easily might hit the 100 link limit; there is no penalty for that but still it is a good rule to keep the number of links (both internal and external) below the 100-link mark;
- WordLift is keen on helping you create a good internal linking structure to reduce the bounce rate on your site and to increase the number of pages visited during each browsing session by your readers; if your internal links for the same entity are too many they simply become irrelevant. On the contrary if your article is long enough it is probably good to have 2-3 links pointing to the same entity page (as a reader I might miss the first one and might instead find useful the second or third one).
When should I link one entity to another?
By running the analysis on the property description text of an entity you can link it to other entities. WordLift will store these relationships between one entity and other entities in the graph using the Dublin Core property dct:related. This information will be used to suggest new connections between the contents of your site. Creating links among relevant entities will create more structure for your content, even though it is not mandatory to do so. You should always link entities that can help other users discover relevant contents (i.e. the entity [Berners-Lee] shall be linked to entity [Web] as the two concepts are strictly related.)
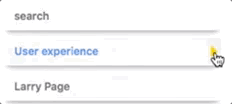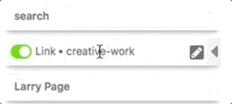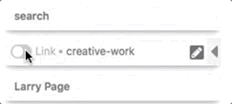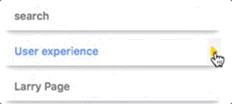
How can I enable or disable links to entities?
You can enable or disable the link to an entity by toggling the "Link" option for each annotation. See below
You can also enable or disable links site-wide from the WordLift Settings screen in the General tab as shown below.
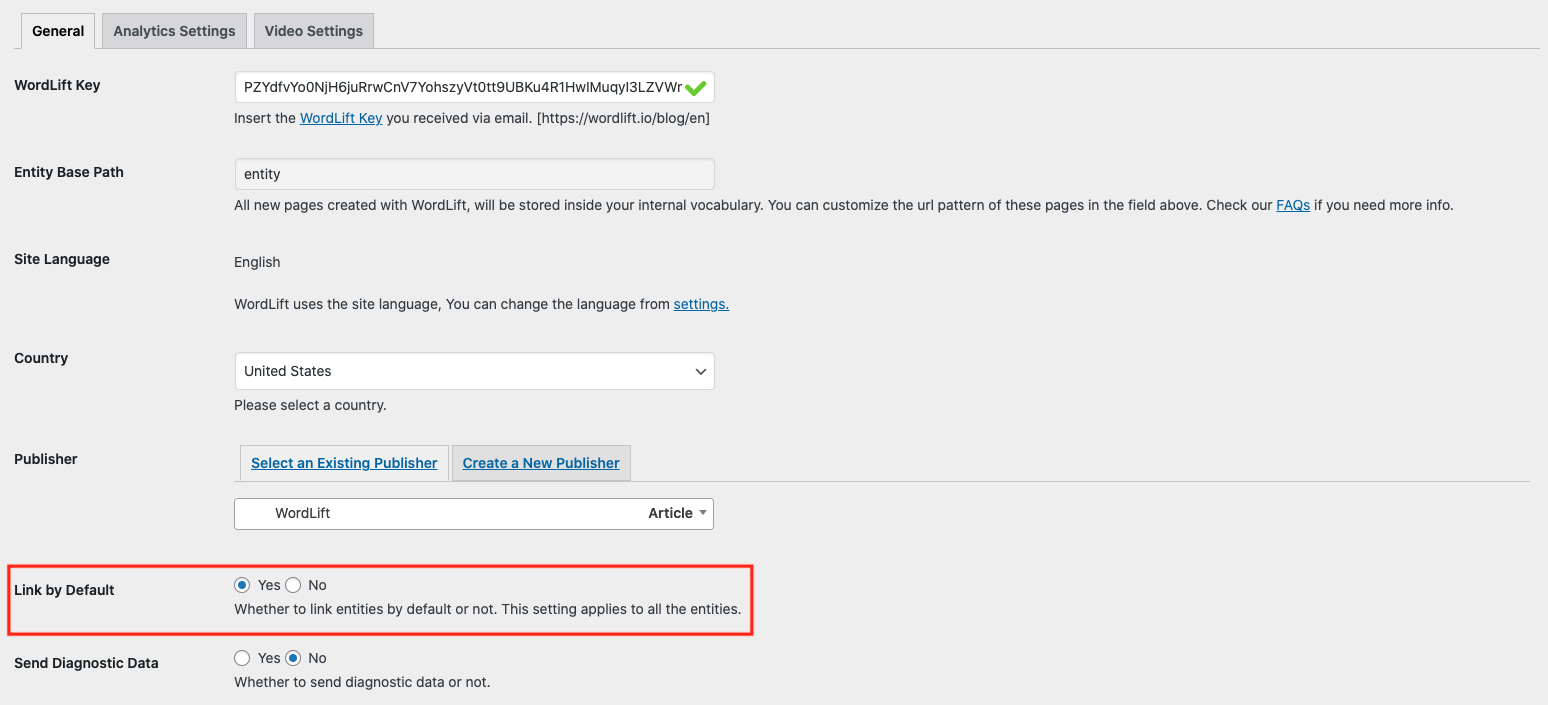
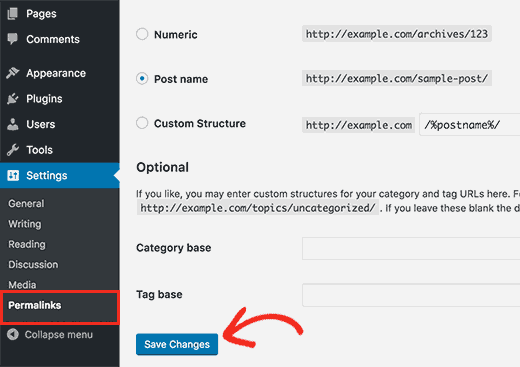
Why do I get 404 error on pages linked by WordLift?
WordPress is a powerful CMS. Nevertheless, in some cases, posts or pages newly created might return a scary 404 Error. Pages created with WordLift are not an exception and you might end up in a situation where WordLift is creating links to pages that apparently do not exist. Don't worry this is a well-known WordPress issue and it can be easily fixed. Head into the dashboard of your website, click Settings » Permalinks and than press the Save Changes button. WordPress will re-generate all the permalinks and the error will be fixed.
Read this article to learn more about this issue from the WPbeginner website.
What are the datasets WordLift uses for named entity recognition?
WordLift by default uses DBpedia and Freebase to detect and link named entities. With a custom configuration, the content analysis services provided by Redlink and available via our professional services, can use any RDF-based graph. It is also possible to use multiple graphs for named entity recognition and dereferencing.
How can I prevent WordLift from creating new entity pages?
The best soution is to convert existing posts, pages and taxonomy terms to entities that will become part of your Knowledge Graph. This way you’ll not create new pages but re-link the existing pages on your web site.
What is a triple?
A triple is a set of three elements: a subject, a predicate, and an object. Triples are linked together to form a graph that is without hierarchy, is machine readable, and can be used to infer new facts. Triples in WordLift describe facts as metadata about an article or an entity.
Are there any integrations with Neo4j?
Neo4j is a graph database. WordLift stores data in a Linked Data store (Apache Marmotta) which provides linked data and SPARQL end-points. As long as Neo4j provides connectors for those interfaces, then an integration is possible.
Do I need to be Administrator to configure it?
Yes. To configure WordLift you will need to have admin privileges.
Which Schema Types does WordLift support?
WordLift, using the Business plan, supports all the schema types listed in the Schema.org vocabulary.
What is the advantage of using a custom domain for publishing the knowledge graph?
With a custom domain, you can publish the Knowledge Graph under a customer-owned domain such as https://data.example.org. For setup options and DNS requirements, see Custom Domain Configuration.
How can I change the JSON-LD @type from Article to NewsArticle in WordLift?
WordLift, allows you to filter the the JSON-LD output before it is sent to the client and change any part of it, e.g. in this specific case::
add_filter( 'wl_post_jsonld', function( $jsonld ) {
// Bail out if `@type` isn't set or isn't `Article`.
if ( ! isset( $jsonld['@type'] ) || 'Article' !== $jsonld['@type'] ) {
return $jsonld;
}
$jsonld['@type'] = 'NewsArticle';
return $jsonld;
} );